图形技术基础
3.4 延迟渲染
参考教程:here
延迟渲染理论理解
与前向渲染管线流程的对比
前向渲染流程
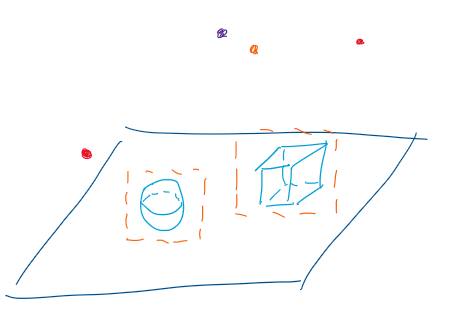
渲染场景:一个球体 一个正方体 4个光源【聚光灯】(红 紫 橙 红)
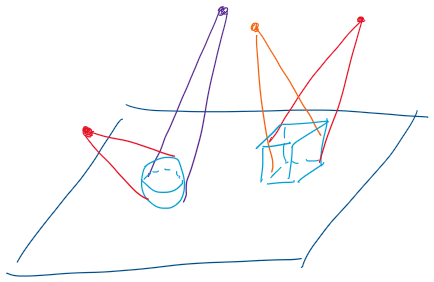
锁定我们即将渲染的物体
执行渲染流程 此时渲染管线共执行4次pass,即对应四个光源 ;灯光直接在片元着色器中计算并叠加至最终结果
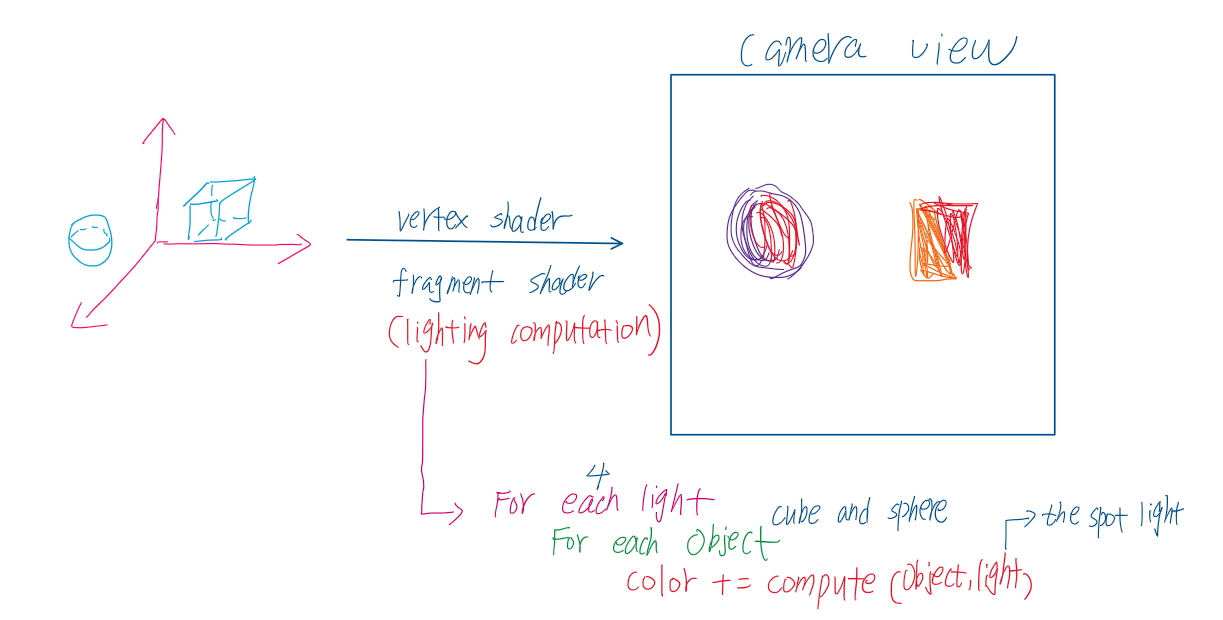
(图中灯光计算参考文章:游戏引擎中的光照算法)
例子运用四个光源,利用图中算法,需要4x2=8次遍历,随着光源和物体数目增多,计算量也会迅速增大(在实际操作中还需处理深度等其他数据信息,时间复杂度可能会剧烈增加)
延迟渲染流程
为弥补上述渲染流程对于大量光源的计算问题,延迟渲染采取两步操作(两个pass)以减小灯光计算量
第一次pass其不进行灯光计算,将可见像素信息(例如深度、法线、基本颜色)输入至GBuffer(可以理解为先将渲染信息保存到一张纹理)
第二次pass,利用GBuffer储存的信息(即已知的可见像素)与光线进行计算
综上所述,延迟渲染将物体和灯光分开计算,即使灯光数量很多,最后实际仅与GBuffer(理解为若干张纹理)进行计算,极大简化了计算流程(我粗浅地理解为解耦)
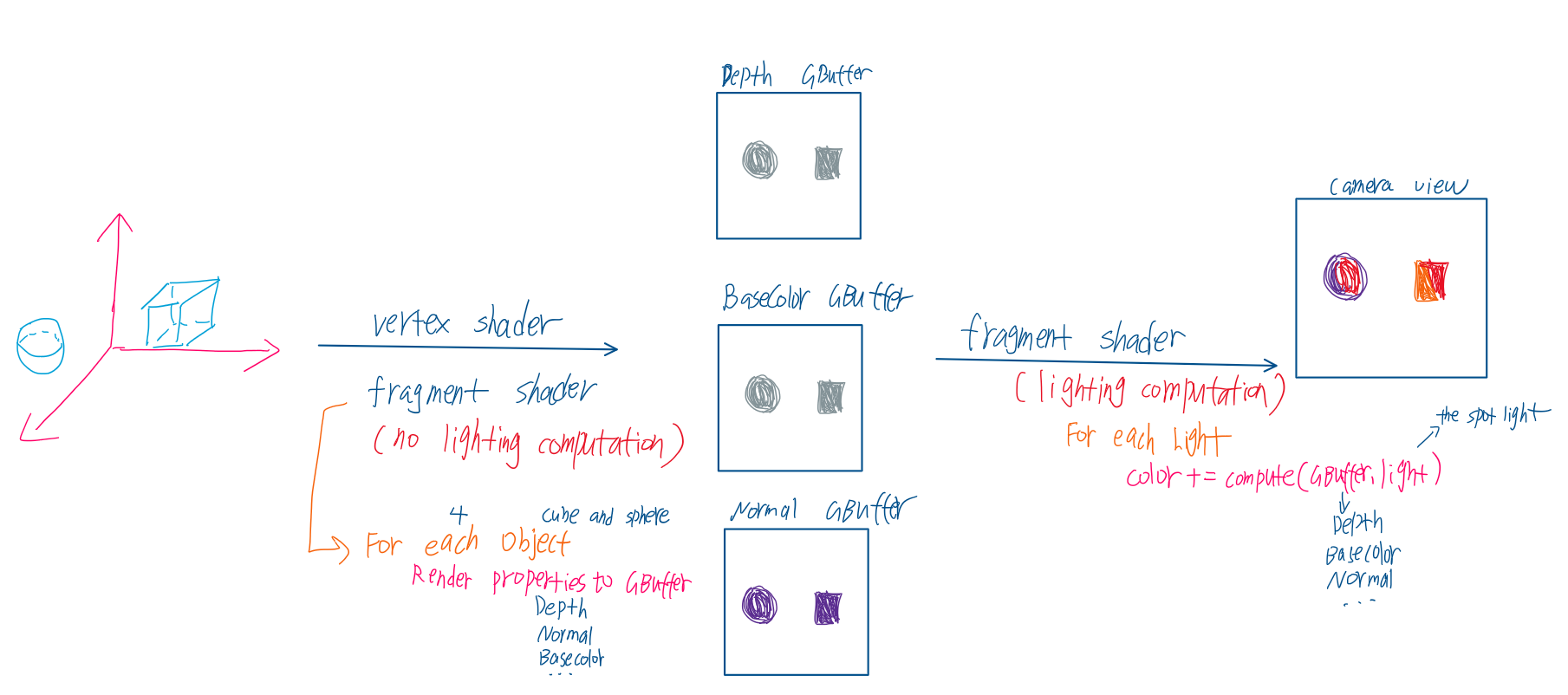
(图中灯光计算参考文章:游戏引擎中的光照算法)
优点vs缺点
经过比较,可以看出延迟渲染针对多光源可以极大减少时间复杂度,但同时这是用空间换时间的做法,为了更精确的渲染结果,GBuffer需要储存的信息会更多,显存带宽也会增加更多。
GBuffer提前计算了很多信息,例如深度,这对于后处理等屏幕空间的操作是意外之喜,但由于GBuffer信息是固定的,即已经是经过光栅化的结果,则不能利用MSAA进行超采样抗锯齿
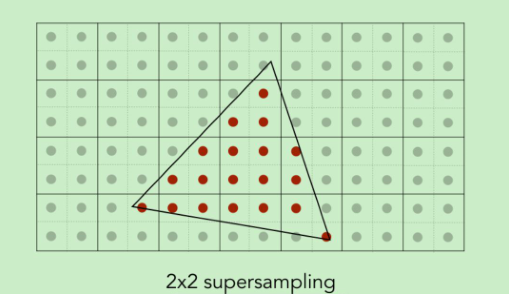
推荐阅读:FXAA、FSAA与MSAA有什么区别 -文刀秋二
移动端的优化
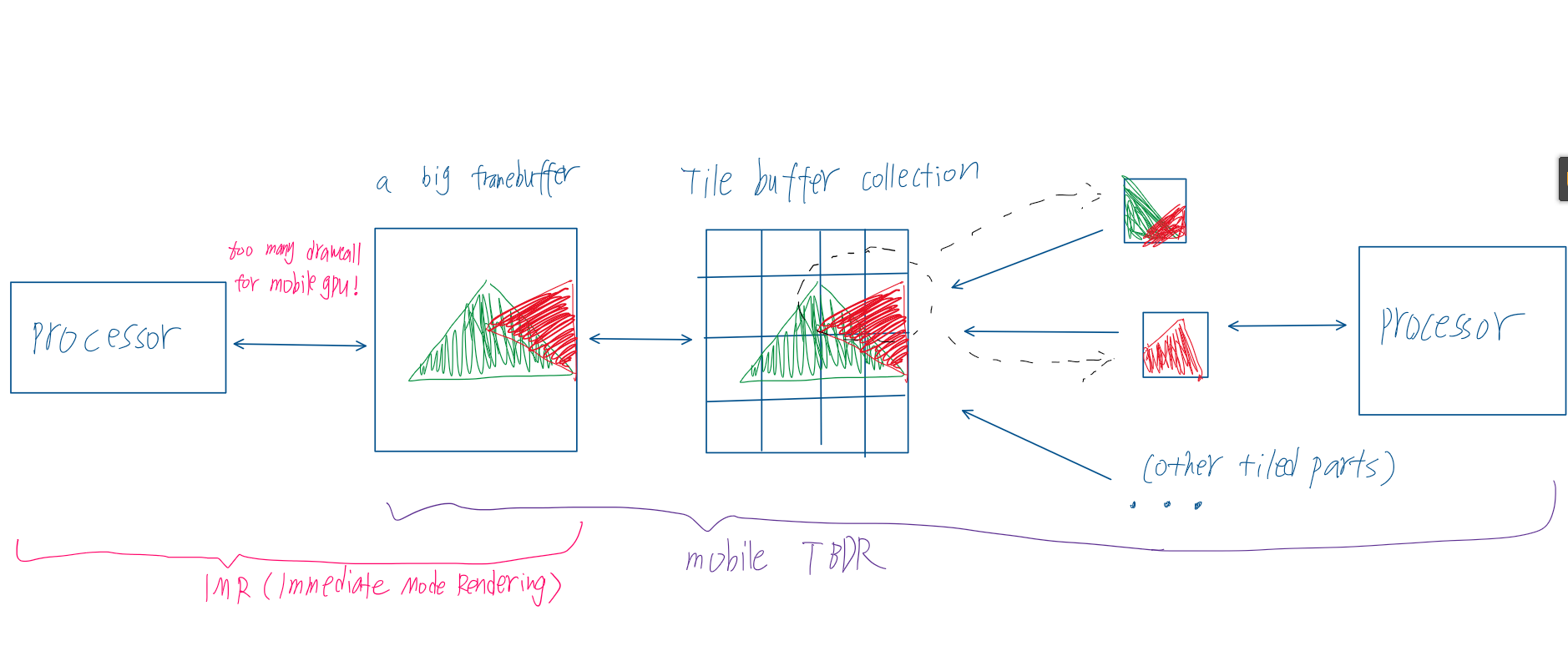
TBDR(Tile-Base-Deffered-Rendering)
目的:减少draw call调用以降低移动端GPU负荷,避免渲染画面时手机过热甚至死机
为减少draw call调用,移动端gpu的方法是将整体FrameBuffer拆分为多个小块(Tiled FrameBuffer),当每一个小块均被处理后(shading),输出整个FrameBuffer,下图为IMR(从左到右至framebuffer)和TBDR(从右到左至framebuffer)对比
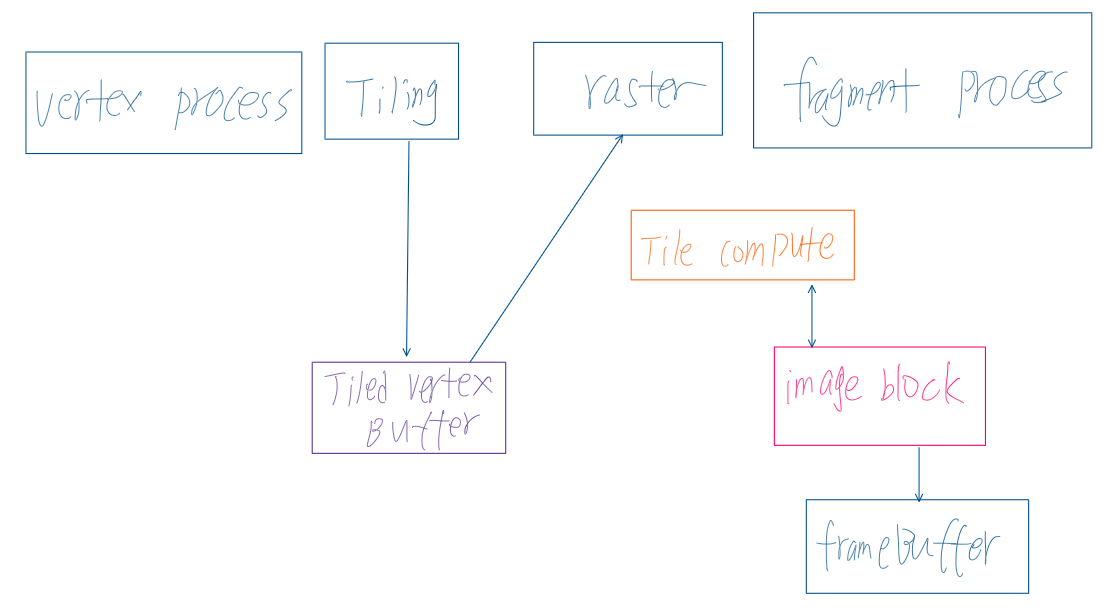
TBDR简化版流水线如图(忽略其他数据处理部分,如深度检测、剔除等):
# Phase one : Tilling Phase
'''
For the entire render pass
1、split viewport into a list of tiles
2、shade all vertices
3、bin transformed primitives into tiles
'''
for draw in renderPass:
for primitive in draw:#针对片元
for vertex in primitive:
execute_vertex_shader(vertex)
if primitive not culled:#若片元未被剔除,就加入tile list待后续处理
append_tile_list(primitive)
# Phase two : Rendering Phase
'''
For each tile in the render pass
1.load action(or clear)
2.rasterize
3.shade visible pixels
4.store(or don't care)
'''
for tile in renderPass:
for primitive in tile:#tile buffer(即每一小块framebuffer)中的片元
for fragment in primitive:
execute_fragment_shader(fragment)
Tilling Phase:

(图片来源:移动端高性能图形开发 - 移动端GPU架构探究 - 知乎 (zhihu.com))
shader优化
以下总结(包括图片来源)自:Unity性能优化专场
避免隐式转化 : int4(x)+1.0->float4(int4(x)+1.0)->int4(float4(int4(x)+1.0))

标量数据转换为向量,提高硬件读取效率
不要忽略shader指令缓存,缩短shader着色器代码
shader精度:
顶点精度:减少高精度使用;不把FP32(4字节单精度浮点数)数据上传到一个buffer并低精度读取,会因浪费额外精度而浪费内存储存和带宽;顶点position需要额外精度,使用FP32计算顶点位置
VS输出数据(varying)精度(仅建议):低精度存储法线切线、顶点色、小于等于512x512的纹理uv;高精度存储世界坐标、大纹理uv或wrap mode为repeat的uv
Buffer与寄存器:减少shader寄存器使用(Uniform buffer数、变量数);存储需求小时,尽量使用uniform buffer而不是SSBO(Shader Storage Buffer Object) SSBO与UBO区别
Texture Fetch:减少texture fetch;尽量避免随机访问;压缩纹理;使用mipmap;访问3D纹理代价高;平均看,各向异性过滤消耗是各向同性2倍
Branching:减少动态分支语句(if与分支);静态分支可接受;提前退出的分支语句有时可提高性能
Loop:unroll优化,但代价是增加寄存器用量(HLSL 关键词branch flatten unroll loop);ray marching每个循环多次步进
low GPU occupancy(GPU占用率低):shader耗尽内部资源(如线程、寄存器);shader简单,线程执行完毕速度>GPU创建新线程,来回切换;渲染物体占屏幕较小区域(shadow map中shadow distance过长,物体占用shadow map像素过小),分发较小线程组(thread group),GPU无线程可创建
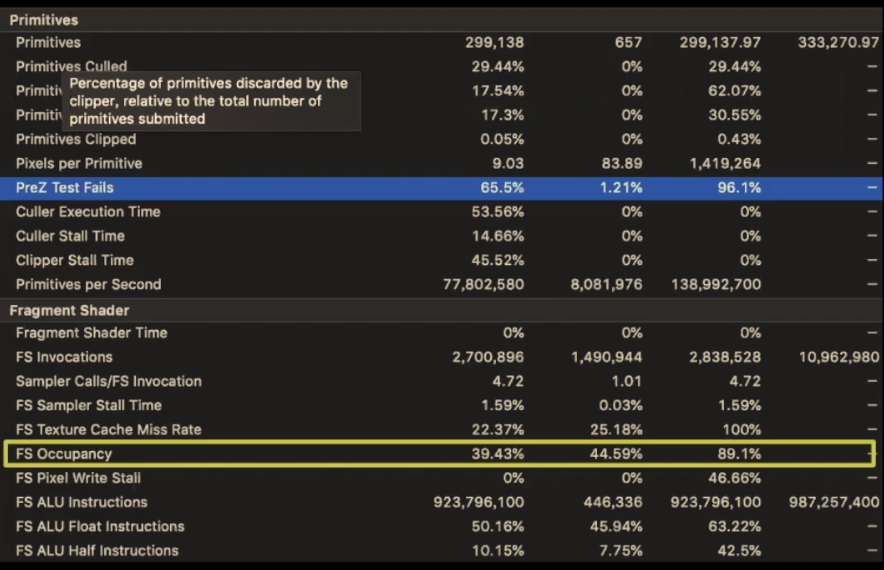
GPU latency(GPU延迟)
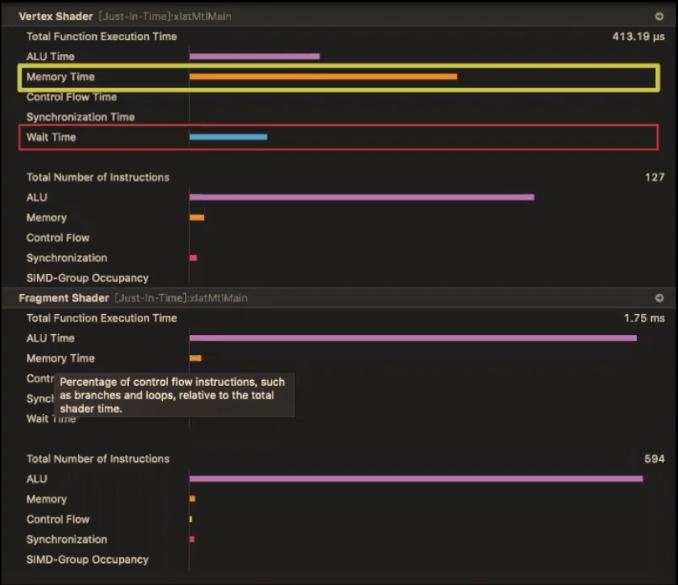
针对Fragment Shader:烘焙必要数据至查询纹理(look up texture),采样此纹理增加memory fetch时间活得结果代替ALU时间
TBR GMEM Load:
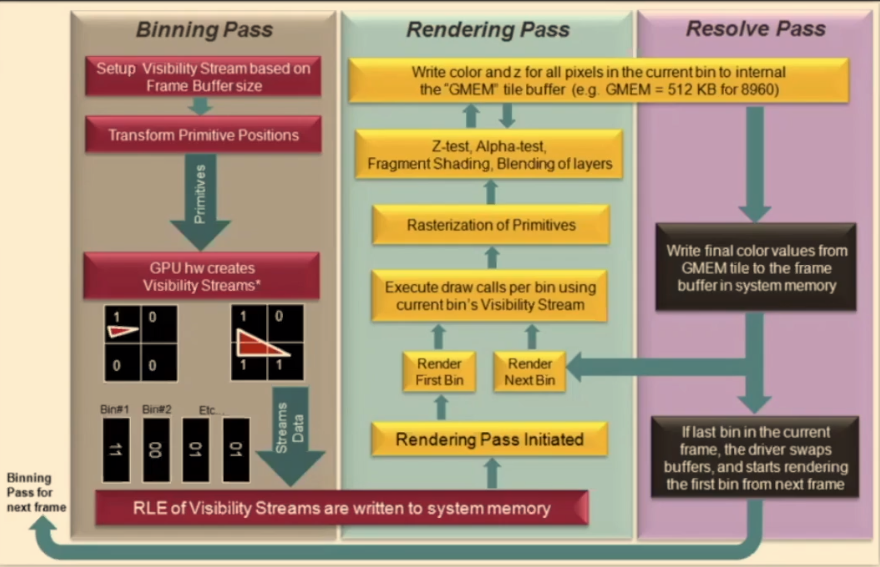
GMEM(The GMEM is the local memory of the GPU and is used for fast Z, color, and stencil rendering. )
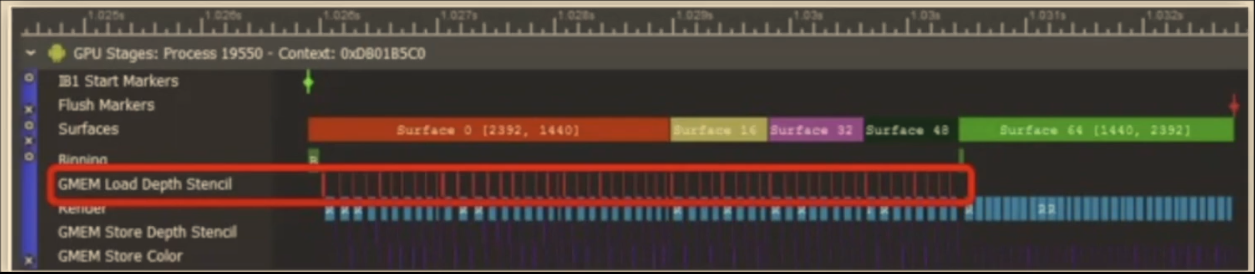
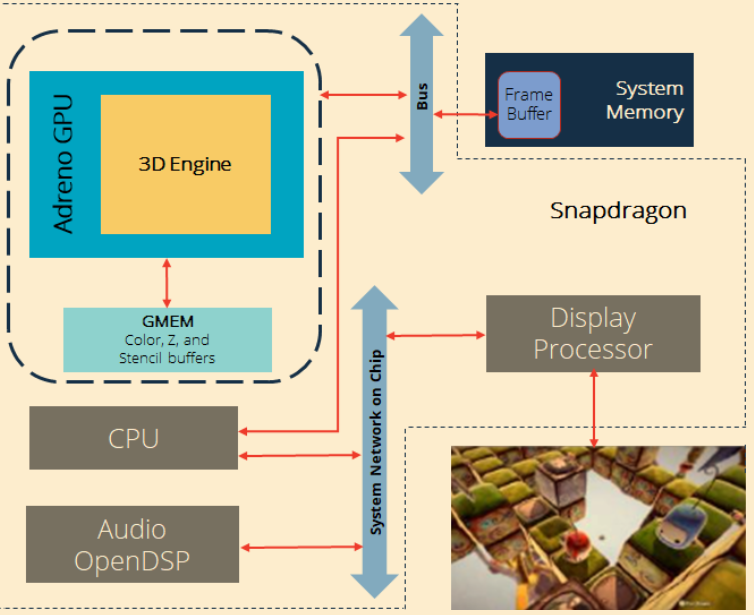
GMEM Store&Load:pass开始时,clear每个FBO;clear FBO全部内容(color,depth,stencil)以快速清除tile memory;对渲染到frame buffer的一个子区域,使用scissor scissor设定需要的clear或rendering区域;不要在一帧多次切换渲染到同一个FBO
Overdraw:不透明物体排序(console&PC);不透明物体不排序(PowerVR GPU - HSR - Hidden Surface Removal ; Mail - FPK -Forward Pixel Kill ; Adreno - Low Resolution Z Pass)
移动端高性能图形开发 - 移动端GPU架构探究 - 知乎 (zhihu.com)
[Unity 活动] - 线上分享会 — 性能优化专场【回放】_哔哩哔哩_bilibili
扩展阅读:
IMR, TBR, TBDR 还有GPU架构方面的一些理解 - 知乎 (zhihu.com)
移动设备GPU架构知识汇总 - 知乎 (zhihu.com)
为什么时至今日仍有人质疑手机的图形性能? - 知乎 (zhihu.com)
存疑
分支和循环的优化手段:branch flatten 静态分支和动态分支区别 ,unroll loop 循环展开和不展开具体指什么